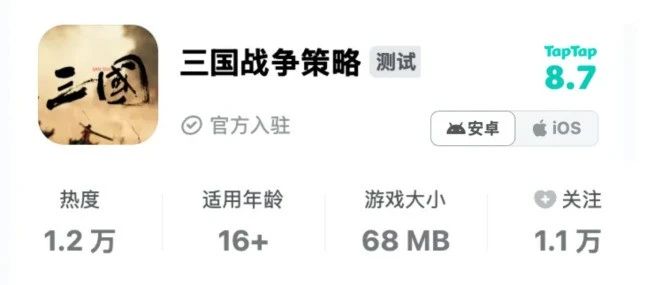
一个人+AI,TapTap8.7分|独立游戏《三国战争策略》专访
从最初的“理想很丰满,现实很骨感”,到现在能够熟练运用 AI 工具助力开发,陈先生的经历告诉我们:在 AI 时代,独立开发者的道路虽然依然充满挑战,但也充满了新的机遇。
2025.04.11
从最初的“理想很丰满,现实很骨感”,到现在能够熟练运用 AI 工具助力开发,陈先生的经历告诉我们:在 AI 时代,独立开发者的道路虽然依然充满挑战,但也充满了新的机遇。